Relationales Datenbankmodell
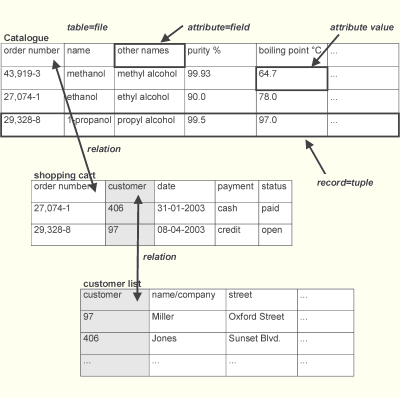
Bei diesem Modell sind die Daten unabhängig von der Struktur der Datenbank. Die Informationen sind in Tabellen gespeichert, die in Reihen (records/tuples) und Spalten (fields/columns) gegliedert sind. Die Reihen enthalten den jeweiligen Datensatz, den Spalten sind die Attribute zugeordnet. Zu den eigentlichen Einträgen werden Meta-Daten (also Daten über Daten) abgespeichert. Jede Tabelle besitzt einen eindeutigen Namen, der bei einer Suche ansprechbar ist. Durch das Ergänzen oder Entfernen von Tabellen kann die Struktur der Datenbank auch nachträglich noch angepaßt werden.
Relationale Datenbanken nutzen den verfügbaren Speicherplatz sehr effektiv, da sie wenige redundante Informationen enthalten. Der entscheidende Vorteil ist die große Variabilität der Struktur.
© Prof. Dr. J. Gasteiger, Dr. A. Schunk, CCC Univ. Erlangen, Fri Nov 21 08:47:40 2003 GMT
 BMBF-Leitprojekt Vernetztes Studium - Chemie BMBF-Leitprojekt Vernetztes Studium - Chemie
|