Data Mining-Methoden in der Chemie
Der Prozess des Data Mining ist in der Chemie nicht neu. Chemiker nutzen seit den frühen Anfängen der chemischen Forschung sowohl eigene Daten als auch Literaturangaben für die Entwicklung von Modellen und zur Vorhersage von Sachverhalten. Die dramatische Zunahme der Größe von Datensätzen fordert jedoch den Einsatz von effektiven, computergestützten Data Mining-Methoden. Dabei kamen zunächst nur klassische Statistikmethoden zum Einsatz. Speziell ausgebildete Statistiker arbeiteten sich mit Hilfe besonderer Softwarepakete durch Unmengen an Daten und versuchten die darin verborgene Information zu extrahieren.
Der dafür notwendige Arbeits- und Zeitaufwand war enorm und führte häufig nicht zum gewünschten Erfolg. Erst durch die Entwicklung schneller Rechnersysteme konnten neue, auf künstliche Intelligenz basierende Analyseverfahren, sogenannte Machine Learning- Methoden entwickelt werden. Die darauf basierenden Techniken erlaubten erstmals die Lösung komplexerer Data Mining-Probleme.
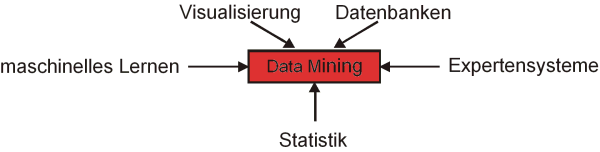
Aufgrund der teilweise sehr diversen Definitionen des Data Mining-Begriffs
gestaltet sich auch eine detaillierte und allgemein gültige
Aufteilung und Klassifizierung der verschiedenen Data Mining-Methoden
als schwierig. So werden je nach Standpunkt des Betrachters statistische
Methoden und Projektions- bzw. Transformationsverfahren entweder
zu den Data Mining-Methoden gezählt oder auch nicht. Darüber
hinaus können die einzelnen Methoden sehr unterschiedlich zusammengefasst
bzw. klassifiziert werden. Eine mögliche Gruppierung geht dabei
von den Machine Learning-Ansätzen aus und unterscheidet beispielsweise
zwischen sogenannten supervised und unsupervised learning-Mechanismen.
Andere Ansätze wiederum unterscheiden die verwendeten Methoden
anhand der zu analysierenden Datentypen (z. B. hierarchisch vs.
nicht-hierarchisch, linear vs. nicht-linear, etc.) oder anhand von
typischen Analysemodellen der Informatik (Sequenzanalyse, Verbindungsanalyse,
zusammenfassende Analyse, Cluster-Analyse, etc.). Aus diesem Grund
und der unüberschaubaren Anzahl an verschiedenen Methoden soll
im Folgenden auf eine detaillierte und genau differenzierte Beschreibung
der einzelnen Data Mining-Techniken verzichtet werden und nur eine
grobe Übersicht der wichtigsten, für die chemische Forschung
relevanten Data Mining-Methoden vermittelt werden. Da nicht jede
Data Mining-Methode für ein gegebenes Analyse-Problem geeignet
ist, muss in der Regel vorher eine Analyse der Stärken und
Schwächen der jeweiligen Technik vorgenommen werden. Darüber
hinaus können durch Kombination diverser Data Mining-Methoden
häufig bessere Ergebnisse erzielt werden.
Die chemische Information wird bei der computergestützten Analyse in der Regel zunächst in eine sogenannte deskriptive Datenstruktur überführt. Diese Datenstrukturen werden auch als molekulare Deskriptoren bezeichnet und sind das Ergebnis mathematischer Verfahren, welche die chemische Information in sinnvolle, numerische Werte überführen. Es existiert eine Vielzahl an molekularen Deskriptoren unter anderen für topologische, elektronische und strukturelle Eigenschaften. Chemische Datensätze enthalten in der Regel eine ganze Reihe solcher Deskriptoren, da komplexe Sachverhalte und Relationen zwischen Datenobjekten nicht ausreichend durch eine oder wenige molekulare Datendimensionen beschrieben werden können. Der sich daraus ergebende, hochdimensionale Charakter der Datensätze setzt jedoch besondere Analysemethoden voraus.
© Prof. Dr. J. Gasteiger, Dr. Th. Engel, CCC Univ. Erlangen, Thu Apr 15 06:31:57 2004 GMT
 BMBF-Leitprojekt Vernetztes Studium - Chemie BMBF-Leitprojekt Vernetztes Studium - Chemie
|