Maschinelle Lernverfahren
Der maschinelle Lernprozess beginnt gewöhnlich mit der Auswahl
eines Datensatzes, der dann in zwei Teilmengen (subsets) aufgeteilt
wird: einen Trainings-Datensatz, der zum Trainieren des Systems
genutzt wird, und einen Test-Datensatz, der die Möglichkeit
bietet die Resultate zu evaluieren. Das maschinelle Lernen erfolgt
durch das Trainieren, wobei aus einem Beispiel des Trainings-Datensatzes
gelernt wird. Danach wird die Qualität des Lernens abgeschätzt,
indem die Fähigkeit des Systems abgewogen wird, die Ausgabe
aus dem Test-Datensatz vorherzusagen. Die Fähigkeit ein Ergebnis
(Output) vorherzusagen, wird allgemein Generalisierung genannt.
Wenn ein System Eingabedaten nur memoriert (abspeichert) und nicht
erfolgreich daraus lernt, kann es nicht generalisieren.
Der zugrunde liegende Lernprozess kann unterschiedliche Konzepte
verfolgen, wobei die zwei Hauptstrategien das "überwachte"
und das "unüberwachte" Lernen sind.
Unüberwachtes Lernen
Das Ziel des unüberwachten Lernens (ohne Unterweisung) ist,
daß eine Maschine oder ein System aus eingegebenen Daten eine
Darstellung erzeugt. Diese kann dann benutzt werden, um z.B. Cluster
(Anhäufungen) innerhalb der Daten aufzuspüren, Ausreißer
zu erkennen oder die Dimensionalität zu reduzieren. Die Methoden
die hierfür benutzt werden sind zum einen Kohonen Netze (Typ
an neuronalen Netzen, die auch selbst organisierende Karten (self
organizing map = SOM) genannt werden) oder konzeptionelles Clustering
(Daten werden in Gruppen zusammengefasst).
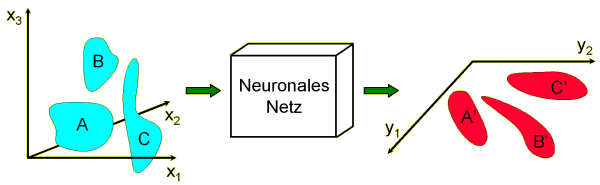 |
Beim Lernen ohne Unterweisung werden die Eingabedaten so lange über das Netzwerk geschickt, bis sich die Ausgabedaten stabilisiert haben und die Eingabewerte ein Objekt in bestimmte Bereiche des neuronalen Netzes abbilden. |
Überwachtes Lernen
Ziel des überwachten Lernens (mit Unterweisung) ist, daß
ein System lernt, Eingabedaten mit den entsprechenden Ziel- oder
Ausgabendaten zu assoziieren. Zusätzlich zu den Eingabedaten
wird der Maschine auch ein Satz Zielausgaben gegeben. Soll für
eine neue Eingabe eine korrekte Ausgabe generiert werden, werden
beide alten Datensätze eingesetzt. Die neue Ausgabe des Systems
wird dann mit der korrekten Ausgabe verglichen, wodurch ein Fehler
erhalten wird. Überwachte Lernmaschinen versuchen diesen Fehler
zu minimieren.
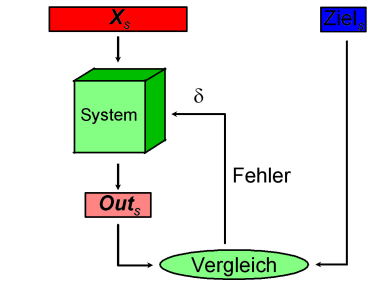 |
Beim Lernen mit Unterweisung (überwachtes Lernen) werden dem neuronalen Netz eine Reihe von Objekten präsentiert und ihm zu den Eingabedaten X dieser Objekte die zu erwartenden Ausgabewerte Y im Ziel vorgegeben. Ein Vergleich mit den Erwartungswerten liefert einen Fehler von der Größe d. Dieser entscheidet dann über die Notwendigkeit weiterer Anpassungscyclen, wobei die Gewichte im neuronalen Netz so angepaßt werden, daß für den Satz an p bekannten Objekten die Ausgabewerte des neuronalen Netzes möglichst gut mit den Erwartungswerten Y übereinstimmen. |
Überwachtes Lernen kann zur Klassifikation, zum Modelling oder zur Vorhersage benutzt werden. Übliche Methoden die überwachte Lernstrategien nutzen, sind Eintscheidungsbäume, Genetische Algorithmen (GA) und Counter- bzw. Backpropagation neuronale Netze.
Beispiele für überwachtes und unüberwachtes Lernen in maschinellen Lernverfahren
|
Unüberwachtes Lernen
|
Überwachtes Lernen
|
- Kohonen Netz
- Konzeptionelles Clustering
- Hauptkomponentenanalyse (PCA)
|
- Entscheidungsbäume
- Partielle kleinste Quadrat Regression (PLS)
- Multiple lineare Regression (MLR)
- Counterpropagation Netz
- Backpropagation Netz
- Genetische Algorithmen (GA)
|
© Prof. Dr. J. Gasteiger, Dr. Th. Engel, CCC Univ. Erlangen, Thu Apr 15 06:31:57 2004 GMT
 BMBF-Leitprojekt Vernetztes Studium - Chemie BMBF-Leitprojekt Vernetztes Studium - Chemie
|