Hashcode
Unter einem Hashcode versteht man in der elektronischen Datenverarbeitung
die komprimierte Darstellung einer komplexen Informationseinheit
mit fester Länge. Im Unterschied zu einem Datenkompressionsalgorithmus
kann aus einem Hashcode die ursprüngliche Information nicht
wiedergewonnen werden.
Das Hash-Verfahren (Schlüsseltransformation) berechnet aus
alphabetischen, numerischen oder alphanumerischen Schlüsseln
eine Menge von Speicheradressen. Dabei werden die Daten bzw. Strukturen
in Fragmente aufgeteilt, die wiederum eine Identifikationsnummer
(ID) zugeordnet bekommen. Diese ID der Fragmente ist aber nicht
direkt im Computer zugänglich. Sie muß erst durch einen
Hash-Algorithmus in eine vorgegebene, feste Anzahl von Zeichen (Hashcode)
transformiert werden. Der verschlüsselte Code ist mit einer
definierten Länge, d.h. feste Bit/Byte-Länge (z.B. 32
Bit oder 64 Bit) angegeben. Diese extreme Datenreduktion ist eine
effiziente Methode zur Verwaltung großer Datenmengen.
Der Hashcode wird somit nicht als direkter Datenzugriff benutzt,
er dient vielmehr als Index oder Schlüssel zum abgelegten Dateneintrag.
Da dieser Schlüssel in eindeutiger Weise erhalten wird, indem
mehrdimensionale Daten in eine einzige Dimension reduziert werden,
geht beim Hash-Coding Information verloren. Dieser Verlust verhindert
eine Rekonstruktion der vollständigen Daten aus dem Hashcode.
Über einen Hashcode-Algorithmus wird aus der Vollstruktur
eines Moleküls eine eindeutige Integerzahl mit bestimmter Bit-Länge
berechnet, d.h. der Algorithmus liefert für identische Molekülstrukturen
immer die selbe Integerzahl. Ein Hashcode ist somit eine eindeutige
Zahl, die in der Chemie molekulare Datenstrukturen wie Atome und
Bindungen beschreibt und identifiziert, oder für eine bestimmte
chemische Struktur charakteristisch ist. Dadurch eignet sich der
Hashcode u.a. bei einer Suche zur schnellen Überprüfung
der Identität von Strukturen.
Durch die festgelegte Zeichenzahl (Bit-Länge) können allerdings
mehrere unterschiedliche Molekülstrukturen auf den gleichen
Hashcode abgebildet werden ("adress collision"). Die Kollisionswahrscheinlichkeit
steigt, wenn die Anzahl der Eingabedaten im Verhältnis zum
Wertebereich (Bit-Länge) erhöht wird.
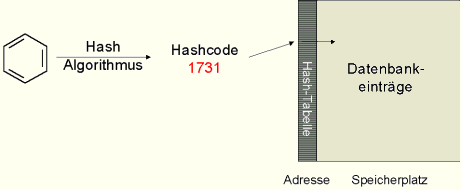
Suche einer chemischen Struktur mit Hilfe eines
Hashcodes
Im Allgemeinen werden Hashcodes im Chemie-Informationsprozess zur
Molekülidentifikation und zur Erkennung von gleichen Molekülen
bzw. Atomgruppen genutzt.
Der Hashcode mit bestimmten Eigenschaften bietet zahlreiche Möglichkeiten
zum Gebrauch:
- Bereits vorberechnete Molekül-Hashcodes sind in Datenbankanwendungen
für Voll- und Substruktursuche geeignet. Durch die kompakte
Codierung einer chemischen Struktur in einer einzigen Zahl ist
es auch möglich, die Transformationsresultate für einen
ganzen Katalog im voraus zu berechnen, in Dateien bereitzuhalten
und zur Programmlaufzeit vollständig im Kernspeicher zu halten,
wodurch eine Suche in sekundenschnelle durchgeführt werden
kann.
- Atom- und Bindungs-Hashcodes sind für Strukturmanipulationsprogramme
z.B. in der Reaktionsvorhersage oder im Synthesedesign hilfreich.
© Prof. Dr. J. Gasteiger, Dr. Th. Engel, CCC
Univ. Erlangen, Thu Dec 18 14:53:53 2003 GMT
 BMBF-Leitprojekt
Vernetztes Studium - Chemie BMBF-Leitprojekt
Vernetztes Studium - Chemie
|